12. Oktober 2012
Rudimentary Recognition of Spoken Words at KTH
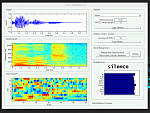 Pattern recognition (EN2202) at KTH Stockholm turned out to be a very good course, concerning lecture, exercises, and the accompanying project work. Together with a fellow student, we created a rudimentary recognizer for spoken words. It is far from production quality, of course. While a good part of the coding has been prepared for the students, the task left enough freedom to play around with hidden markov models in the context of word recognition.
Pattern recognition (EN2202) at KTH Stockholm turned out to be a very good course, concerning lecture, exercises, and the accompanying project work. Together with a fellow student, we created a rudimentary recognizer for spoken words. It is far from production quality, of course. While a good part of the coding has been prepared for the students, the task left enough freedom to play around with hidden markov models in the context of word recognition.
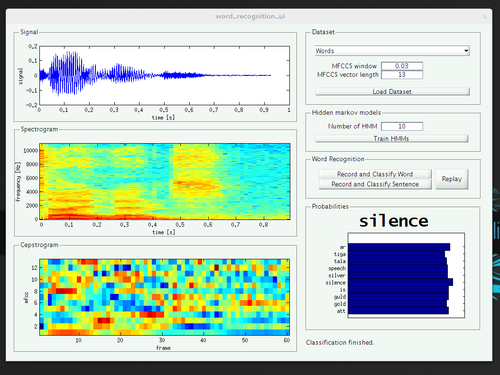
The word recognition task is quite challenging. While some of the code for the hidden Markov models was provided to us, we still had to face different sources of variance. Variance between a spoken word from the same speaker, variance between spoken words of different speakers, not to forget the difference between females and males. Last, but not least, the microphones recording one’s speech have different noise profiles too.
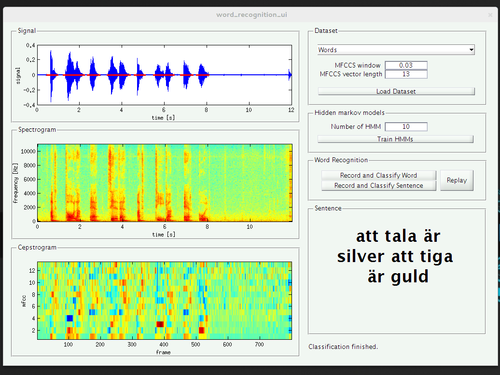
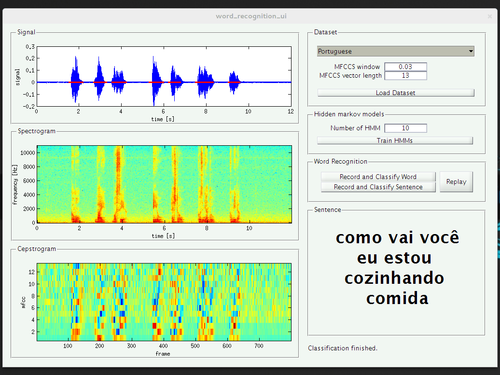
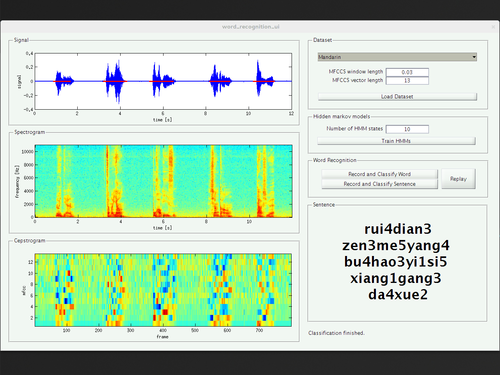
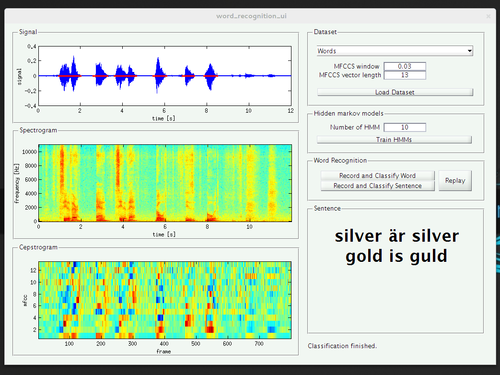
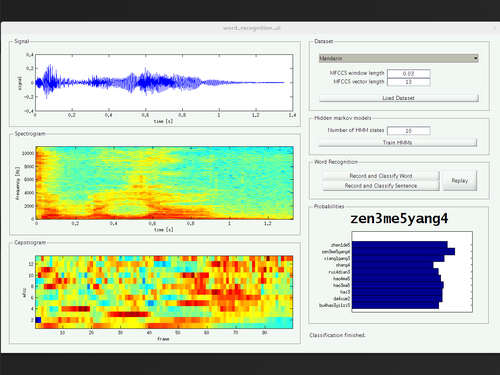
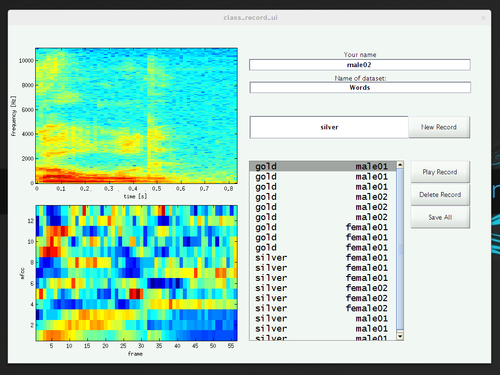
In order to address the various sources of variability, we tried to make the collection of training data as simple as possible, thereby exploring MATLAB’s limited capabilities of creating a graphical user interface. This way, we could record samples from four speakers of three different mother tongues, of different genders, and with two different native languages.
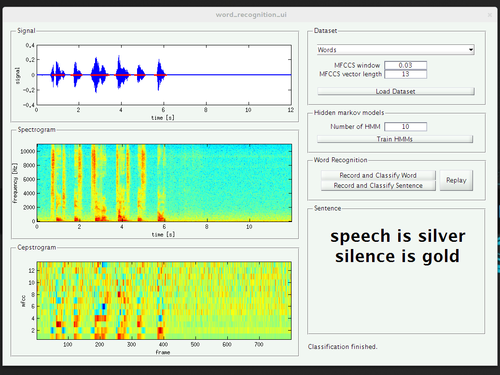
We did not really do a quantitative evaluation of the performance of the system yet, but it feels like the efforts pay out. The performance of the recognizer trained with words from a single speaker seems to be strongly biased to that speaker (meaning that it won’t work for speakers it was not trained for) while the system successfully recognized the words said by volunteers during the presentation.